

I3: Image-Text Interleaved Instruction Following Challenge
I3: Image-Text Interleaved Instruction Following Challenge
Title
I3: Image-Text Interleaved Instruction Following Challenge
Visit Grand Challenge Website (Program)
Abstract
We introduce the I3 Challenge, defined as a benchmark for image- Text interleaved instruction following, to ACM Multimedia Asia 2025. The I3 Challenge aims to assess the ability of models and systems to comprehend demonstrative instructions consisting of multiple, interleaved, and multimodal context that demonstrate the required information to complete a task. Accompanying the challenge is the extensive I3 Dataset, comprising 448K high-quality demonstrative instruction-response pairs across 29 sub-tasks. These pairs are curated from a diverse array of multi-modal datasets, spanning various fields and scenarios, to ensure comprehensive coverage and challenge diversity. The challenge encompasses seven major task categories, designed to test a wide range of capabilities in the vision-language domain: 1) Multi-Modal Dialogue, 2) Visual Storytelling, 3) Visual Relation Inference, 4) Multi Modal Cloze, 5) Knowledge Grounded QA, 6) Text Rich Images QA, 7) Multi Image Reasoning. Hosting the I3 Challenge at ACM Multimedia Asia 2025 serves not only to engage a broader audience in this burgeoning field but also to significantly benefit the academic, industry, and societal communities at large. This initiative is set to drive significant progress and inspire broad involvement in creating advanced vision-language models.
Background and Motivation
General-purpose vision-language pre-trained models (VLMs) have achieved remarkable progress [1, 10, 21, 25, 36, 39]. Recent iterations of VLMs typically enhance a large language model (LLM) by integrating a visual encoder, revealing impressive zero-shot performance across a range of visual tasks. While these Multimodal Large Language Models (MLLMs) exhibit notable capabilities, they mainly concentrate on vision-language instructions that only involve a single image as visual context and limited instruction diversity, thus limiting the applicability of such instruction-following assistants. However, in real life, humans typically express their requirements through a series of related images and texts. For example, people might ask models to solve an open-domain task by referring to multiple sources of multi-modal information (e.g., visually-rich web-pages, textbooks, lecture slides). These varied references and the question constitute demonstrative instructions, where multiple, interleaved, and multimodal instructions demonstrate the required context to complete a task.
To facilitate research in interleaved vision-language instruction following, we build I3, a comprehensive challenge of 29 tasks with varied, demonstrative instructions in a unified instruction-response format, covering 20 diverse scenarios. As depicted in Figure 1, I3 has three important properties: (1) Interleaved vision-language context, all the instructions comprise sequences of interconnected images and texts, such as storyboards with scripts, and textbooks with diagrams. (2) Diverse forms of complex instructions, ranging from generating dialogue for comics, identifying disparities in surveillance images, to engaging in conversational embodied task. (3) Vast range of instruction-following scenarios, the benchmark encompasses multiple real-world scenarios, including cartoons, industrial images, driving recordings, recipes, etc. Through holding I3 challenge, we hope to bring the following benefits to the academic community, industry and society:
For the academic community. The I3 challenge spurs groundbreaking research in multimodal learning, thereby enhancing AI systems’ ability to decode and synthesize intertwined visual and textual information. By providing a comprehensive dataset, it serves as a critical resource for the development and evaluation of MLLMs. The DEI3MON challenge includes a diverse set of tasks ranging from constructing narratives based on image sequences, to dialogues that weave together visual and textual elements, and deciphering dense text within images for question answering. Such tasks play a crucial role in advancing the development of versatile MLLMs to better suit real-world multimodal scenarios.
For industry. The insights gleaned from the research and development efforts spurred by this challenge can lead to the creation of more advanced AI products and services. This initiative is set to transform user interfaces by making them seamlessly integrate visual and textual information, thereby improving user interactions across various platforms, including virtual assistants, automated customer service and interactive support platforms. Moreover, the deployment of advanced multimodal models, which excel in processing and acting upon complex, intertwined instructions, promises significant efficiency gains. Industries such as manufacturing, healthcare, and surveillance stand to benefit greatly from these developments, as they enhance decision-making processes and operational effectiveness.
For society. The I3 challenge promotes technology’s accessibility and intuitiveness, significantly aiding individuals with disabilities by creating AI systems proficient in a broad spectrum of instructional content. For example, in the realm of education, AI systems equipped with capabilities for Visual Storytelling and Text-Rich Images QA can revolutionize learning tools. They could provide dynamic, personalized experiences by constructing narratives from sequences of images or extracting vital information from text-dense educational materials, accommodating diverse learner needs. Similarly, in office environments, Multi-Modal Dialogue and Knowledge Grounded QA tasks could transform how professionals interact with digital content, enhancing productivity. These capabilities allow for more efficient information retrieval from complex documents and facilitate interactive, informed discussions based on multimodal inputs—be it in preparing presentations, analyzing reports, or navigating through extensive digital archives. Such innovations ensure content, whether for education or professional use, is more inclusive and engaging, ultimately enhancing outcomes and accessibility for all segments of society, including those with learning disabilities or other challenges that traditional resources may not fully address.
Hosting the I3 challenge aims to push multimedia research forward and generate real-world impacts, enriching technology’s societal role and sparking innovation across various domains.

Challenge Overview
To thoroughly evaluate the interleaved vision-language instructionfollowing ability, we extensively gather a wide variety of multimodal datasets from various fields and scenarios. As illustrated in Figure 1, our I3 challenge covers 29 tasks of 7 categories across different scenarios (i.e., surveillance, web-page, industrial, cartoon, etc.). Note that some datasets (i.e., ALFRED, VISION, OCR-VQA) are not initially designed for the task that involves interleaved imagetext sequences. To further enhance task diversity, we meticulously formulate specific rules to adapt them to desired tasks, strictly following the original annotations. Below is an introduction to these seven categories of tasks:
Visual Storytelling. This task involves creating a coherent narrative based on a series of images presented in sequence. It tests the model’s ability to understand context, sequence, and the progression of events from visual inputs, requiring the construction or prediction of a story continuation.
Multi-Modal Dialogue. In this task, the model must engage in a dialogue that necessitates the interpretation of both visual content and text. It assesses the model’s ability to integrate multimodal information and apply it within a conversational context to make decisions or respond to queries.
Visual Relation Inference. The objective is to identify and articulate the relationships or changes between two pictures. This task challenges the model to observe details and analyze the visual information to determine counts, positions, or interactions. Text-Rich Images QA. This task requires the model to extract and comprehend information from text-heavy images, such as slides or documents. It demands capabilities in text recognition within images and the subsequent application of this information to answer related questions.
Multi-Image Reasoning. The model is tasked with analyzing multiple images to make judgments about them, such as assessing whether they share a similar style or theme. It tests the model’s ability to process and compare visual elements, and to make inferences based on visual data.
Multi-Modal Cloze. This task presents the model with a sequence of images or text with a missing element, requiring the correct identification of the subsequent part from the provided options. It evaluates the model’s understanding of narrative structure and context comprehension to logically fill in the missing pieces.
Knowledge Grounded QA. The model is challenged to answer questions based on complex diagrams or authoritative text sources. It necessitates a comprehensive understanding of the material and the extraction of relevant information to provide accurate responses.
Considering the characteristics and difficulty of the tasks, we categorize Visual Storytelling, Multi-Modal Dialogue, and Visual Relation Inference as open-ended generation tasks. For the other four tasks, we will provide options, treating them as selection tasks.
A brief summary of I3 is present in Table 1.
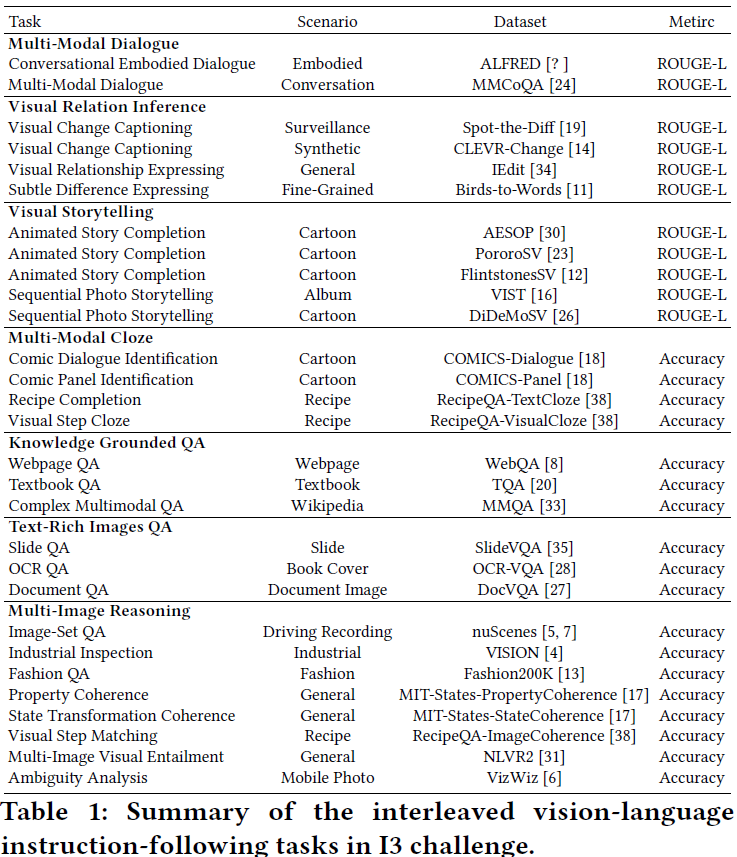
Dataset Specification and Evaluation

We take a maximum of 500 instances per task (referred to as I3-test) and remaining data is used as the training set (referred as I3-Train). Table 2 details the statistics for the challenge. In total, I3 includes 29 tasks and 448.9K instruction-response pairs, serving as a large-scale resource for interleaved vision-language instruction following.
Annotation Format. All task instances are provided to the models in a unified instruction-response form to effortlessly accomplish zero-shot generalization across different tasks. Formally, each instance in I3 consists of the following elements:
• Task_Instruction: provides a complete natural language explanation of a given task, including the input/output structure and the task goal.
• Task_Instance: is a specific example of a given task that consists of intertwined image-text sequential context (e.g., visually-dense textbooks and websites, particular questions about the context).
• Response: represents the desired output in natural language for a given task definition and task example. For classification tasks, we transform the class identifiers as choices into the definition and request the model to output the choice index in natural language as the outcome.
Without any particular emphasis, we use the term “instruction" to denote the combination of Task_Instruction and Task_Instance. For each task, we manually design 10 Task_Instruction templates in natural language to enhance the variety.
Evaluation Protocols. Each participating team is required to submit the following materials: source code (inclusive of test scripts), model checkpoint, a READ-ME document, and their prediction results on the I3-test dataset. To mirror the multifaceted evaluation akin to human examinations, which assess a range of skills through a combination of multiple-choice and open-ended questions, our evaluation strategy encompasses diverse metrics tailored to the nature of the task. For open-ended generation tasks, the evaluation will be conducted using ROUGE-L (F1), assessing the semantic and structural alignment of the generated text with reference texts. For tasks requiring model outputs in the form of option indexes, Accuracy will serve as the evaluation metric, measuring the correctness of selected options. The overall score for each team will be defined as the mean of these scores across all tasks, reflecting a comprehensive measure of performance akin to the scoring of human examinations. This approach ensures a balanced evaluation of both precision in discrete choice tasks and fluency and relevance in generative tasks. Rankings will be automatically generated in real-time, based on the prediction results submitted by participants.
State-of-the-art Techniques Related to I3
We offer an overview of recent technologies. These models are acknowledged as strong multi-modal large language models. We suggest these state-of-the-art systems as references for the contestants.
• GPT-4V [1] expands upon the foundational capabilities of GPT-4 by incorporating visual analysis functionalities, complementing its pre-existing text-based interaction capabilities. It is capable of accepting images as input, facilitating a conversational interaction with users. This interaction can include queries or commands formatted as prompts, instructing the model to execute tasks derived from the visual content of the input image.
• Gemini [36] is a general large model built from the ground up to be multimodal, which means it can generalize and seamlessly understand, operate across and combine different types of information including text, code, audio, image and video.
• LLaVA [25] establishes a connection between the visual encoder ViT-L/14 from CLIP [29] and the language decoder LLaMA [37], utilizing a lightweight, fully-connected (FC) layer. Initially, the system trains this FC layer using 595K image-text pairs, while keeping both the visual encoder and\ LLM static. Following this, LLaVA fine-tunes both the FC layer and LLM using a dataset comprising 158K instructional vision-language pairs.
• MiniGPT-4 [41] bridges the gap between the visual encoder and text encoder using a fully-connected (FC) layer. Initially, this model trains the FC layer on a dataset comprised of 5M image-text pairs before fine-tuning it on 3.5K instructional vision-language data. Notwithstanding its simplicity, MiniGPT-4 requires the loading of a pre-trained vision encoder from BLIP2, as well as a Vicuna LLM [40].
• BLIP2 [21] employs a dual-stage strategy to seamlessly bridge the modality gap, utilizing a lean Q-Former pre-trained on 129 million image-text pairs. The initial stage kick-starts the learning process of vision-language representation, leveraging a frozen image encoder, the ViT-g/14 from EVA-CLIP [32]. Subsequently, the second stage harnesses a frozen LLM, the Vicuna-7B [9], to initiate the vision-to-language generative learning.2023e This innovative strategy effectively facilitates zero-shot instructed image-to-text generation.
• mPLUG-Owl [39] introduces a visual abstractor, fundamentally close the Perceiver Resampler in Flamingo [2], as a bridge between the pre-trained visual encoder ViT-L/14 and the LLM (LLaMA [37]). This model adopts a two-stage finetuning procedure. In the initial phase, both the visual encoder and the visual abstractor undergo comprehensive fine-tuning using a dataset of 204M image-text pairs. Subsequently, in the second phase, mPLUG-Owl applies the 158K LLaVA-Instruct dataset to fine-tune the pre-trained LLM in a parameterefficient manner through the use of LoRA [15].
• InstructBLIP [10] originates from a pre-trained BLIP-2 model, which consists of a ViT-g/14 image encoder, a Vicuna LLM, and a Q-Former to act as the bridge between these two components. During the process of vision-language instruction tuning, only the Q-Former undergoes fine-tuning, with the training process leveraging data from 13 distinct visual question-answering datasets.
• OpenFlamingo [2, 3] represents one of the pioneering efforts to incorporate Language Model Learning (LLMs) into the domain of vision-language pretraining. To optimize its conditioning on visual features, Flamingo strategically integrates a number of gated cross-attention dense blocks amidst the layers of the pre-trained language encoder. Open- Flamingo offers an open-source rendition of this advanced model.
• VPG-C [22] is built upon the frozen LLM and vision encoder. VPG-C (Visual Prompt Generator Complete) first uses the intermediate output of the LLM to infer instruction-specific guidance. This then assists the VPG in attending the missing visual details from the images. By merging these residual details back via a residual connection, VPG-C achieves a thorough grasp of the demonstrative instruction.
Benefits of I3 Challenge
In this section, we will explain how I3 challenge could help accelerate research in vision-language learning.
• Training and Evaluation Resources: I3, with its unique interleaved vision-language context, offers an unparalleled dataset that enables the comprehensive benchmarking of AI’s ability to follow complex, multimodal instructions. It facilitates research by setting new standards in performance for tasks that involve sequences of interconnected images and texts, such as interpreting diagrams in textbooks or story-boarding.
• Attracting Focus: The diversity and real-world applicability of I3’s tasks—from generating comic dialogues to analyzing industrial imagery—draw attention and support from a wide range of stakeholders, including government, industry, and academia. This reflects a collective effort to advance AI research that can navigate the nuances of human communication and instruction following.
• Spread Technology and Knowledge: I3’s emphasis on varied instruction-following scenarios, such as understanding recipes or driving instructions, promotes public interest and encourages collaborations between academic research and practical, industry-driven applications. This exchange not only boosts awareness of AI’s potential in everyday life but also encourages the collaborative development of technologies that are both innovative and accessible.
Organizers
• Zhiqi Ge, Zhejiang University China (gzq@zju.edu.cn)
• Minghe Gao, Zhejiang University China (minghegao@zju.edu.cn)
• Juncheng Li, Zhejiang University China (Jethro9783@gmail.com)
• Wei Ji, Nanjing University China (weiji@nju.edu.cn)
• Siliang Tang, Zhejiang University China (siliang@zju.edu.cn)
© 2025 ACM Multimedia Asia Conference. All Rights Reserved.