

Multimodal Multiethnic Talking-Head Video Generation
Multimodal Multiethnic Talking-Head Video Generation
Title
Multimodal Multiethnic Talking-Head Video Generation
Visit Grand Challenge Website (Program)
Abstract
The "Multimodal Multiethnic Talking-Head Video Generation" Grand Challenge at ACM Multimedia Asia 2025 focuses on multimodal, multiethnic talking-head video generation, aiming to advance methods that generate realistic and expressive talking videos from static reference faces. The task involves creating high-performance models using the DH-FaceVid-1K dataset, which contains diverse, multiethnic video samples, along with audio, text prompts, and facial keypoints. Participants are tasked with training models that integrate strengths from diffusion-based and GAN-based techniques to enhance lip synchronization, identity consistency, speaking style transfer, and inference speed. The goal is to overcome limitations such as poor generalization across ethnicities and slow inference speeds, enabling more lifelike, scalable solutions for applications in video conferencing, filmmaking, and digital humans. Models will be evaluated based on objective metrics such as FID, FVD, lip-sync accuracy, and inference speed. Subjective evaluation will assess identity consistency, video quality, and speaking style controllability. Top performers will be recognized with certificates and an opportunity to submit a paper to ACM MM Asia 2025. The challenge emphasizes multiethnic generalization, particularly for languages like Chinese, and aims to push the boundaries of AIGC in real-world applications.
Motivation & Area review
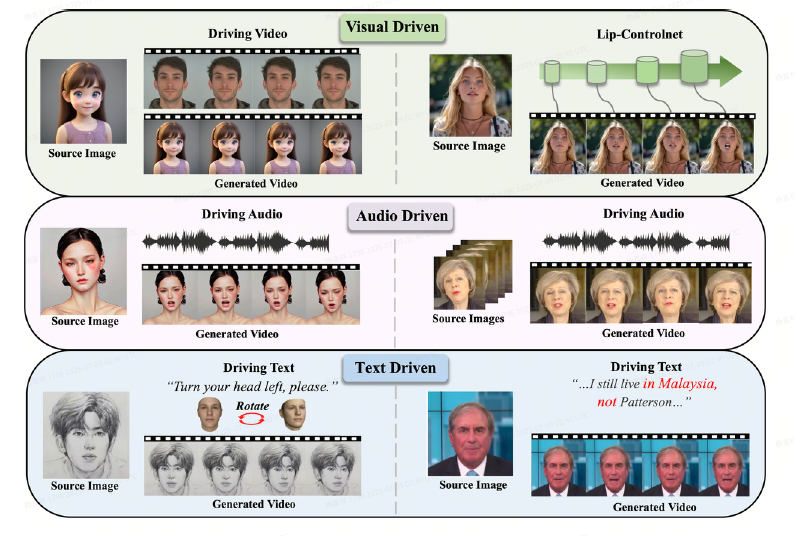
In the era of Artificial Intelligence Generated Content (AIGC), Talking-head video generation has emerged as a popular and challenging topic.
Talking-head video generation aims to synthesize talking videos from a static reference face, conditioned on audio, style frame cues (e.g., emotion and head poses), and other multimodal control signals such as text prompts and facial keypoints, while ensuring precise lip synchronization and faithful reproduction of speaking styles.
Among its various applications, talking-head video generation stands out as a particularly significant domain-specific task with substantial practical value, benefiting many downstream applications such as remote video conferences, filmmaking, digital humans, and multimodal dialogue.
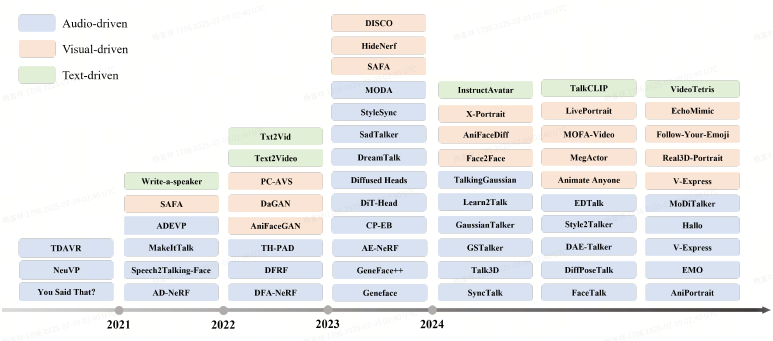
Due to these compelling applications, the field has attracted extensive research interest since 2020 and is expected to remain a key research focus over the next 3–5 years.
When evaluating the performance of a talking-head video generation model, several key aspects should be considered:
1. Lip synchronization accuracy – The precise alignment between the driven audio and the generated lip movements in the video.
2. Identity consistency – The preservation of the source image's facial identity throughout the generated video.
3. Speaking style transfer capability – The model's ability to convey natural variations in emotion, head pose, and movements, making the output more expressive and lifelike.
4. Inference speed – This determines the practicality of the method in real-world applications.
Typically, talking-head video generation methods can be categorized into two genres: diffusionbased methods and other techniques such as GAN-based methods.
Diffusion-based methods typically generate high-quality results with more natural head movements, etc. However, their multi-step denoising nature leads to heavy computational burdens and training overhead, resulting in slower inference speeds (usually below 1 fps). Methods based on other technologies, on the other hand, often rely on carefully designed cascaded modules. These modules usually include audio features and style features, and use these features to predict corresponding 3DMM or FLAME expression parameters. The predicted parameters are then used to warp the source image to achieve the generation goal. Methods based on other technologies generally offer faster inference speeds (some can even achieve realtime performance), but the naturalness and vividness of their generated results are limited, manifesting as relatively fixed head positions, etc. Additionally, their generalization performance is poor: if the source image to be driven differs significantly from the training data distribution, the inference results will exhibit noticeable artifacts and distortions.
Recently, novel methods like VASA-1 have adopted the architecture of diffusion models but predict per-frame motion rather than per-pixel generation. This combines the strengths of both approaches. However, the predicted motion treats the foreground face and background image equally. If the background is complex, this can lead to noticeable background distortion, compromising the fidelity of the generated results.
Overall, mainstream methods often struggle to simultaneously address all four performance evaluation aspects, which limits their practical application in commercial use cases to create truly realistic outputs.
On the other hand, since existing publicly available talking-face video datasets primarily consist of Caucasian faces while exhibiting a significant long-tail distribution for other ethnicities, models trained on these datasets may demonstrate performance degradation when driving faces of other ethnic groups, particularly Asian faces.
The goal of this challenge is to explore next-generation talking-head video generation methods— can they better integrate the strengths of diffusion-based approaches with GAN-based techniques and develop highly generalizable models for multiethnic faces driven by audio in languages like Chinese, as well as other optional modalities such as text prompts and facial keypoints?
Dataset

We provide the DH-FaceVid-1K dataset proposed in our ICCV25 paper titled "DH-FaceVid-1K: A Large-Scale High-Quality Dataset for Face Video Generation" as the training and testing sets.
We offer the following resources:
• Download link for 2000 small-batch sample videos:
https://huggingface.co/datasets/jjuik2014/DH-FaceVid-Sample/tree/main
• Application link for both train and test set requests, participants should clearly indicate their intention to participate in this Grand Challenge in the "Research Field" section: https://docs.google.com/forms/d/e/1FAIpQLSd92kS6ZdAGLoN6DvYUVUDCo7R3Oe6GNVPjQn4sDBPJH7_2_A/viewform
• Project page: https://luna-ai-lab.github.io/DH-FaceVid-1K/
• Github: https://github.com/luna-ai-lab/DH-FaceVid-1K
For the test set, to prevent data leakage from the test set into the training process, we only provide the source face resized to 512×512 resolution, with audio sampled at 16 kHz, text prompts, and facial keypoints.
We ensured diversity in the test set across ages, ethnicities, emotion categories, and head pose variations, while maintaining a sufficiently independent distribution from the training set with no overlap.
For the training sets, we provide per-sample data: video files, talking audio, text prompts, and facial keypoints extracted using DWPose.
Note that we do not constrain the input modalities for training models—you may use audio in combination with any other modalities. Additionally, you can extract other input features such as 3DMM coefficients and phoneme labels from our provided dataset. Please note that using our dataset requires citing our paper:
@inproceedings{di2025facevid, title = {DH-FaceVid-1K: A Large-Scale High-Quality Dataset for Face Video Generation}, author = {Di, Donglin and Feng, He and Sun, Wenzhang and Ma, Yongjia and Li, Hao and Chen, Wei and Fan, Lei and Su, Tonghua and Yang, Xun}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, year = {2025} }
Task
Using the DH-FaceVid-1K dataset we provide, train generalizable high-performance talking-head video generation models, with no restrictions on technical architecture or experimental setups such as the operating system, graphics cards, etc.
After completing the model training, use the trained model to perform inference on the test set samples and submit the generated talking-head videos. Additionally, authors are required to create an online demo page to facilitate our evaluation of each method's specific inference speed.
Evaluation metrics
Below are the objective metrics evaluated on the test set of DH-FaceVid-1K:
• FID (Fréchet Inception Distance)
• FVD (Fréchet Video Distance)
• Inference Speed (frames per second, FPS)
• Sync-C & Sync-D (Synchronization Confidence & Distance for lip-sync quality)
• AKD (Average Keypoint Distance for facial motion accuracy)
• F-LMD (Facial Landmark Distance for expression fidelity)
These metrics quantitatively assess generation quality, temporal coherence, speed, and speaking style transferability in face video synthesis. Participants can use these objective metrics to evaluate model performance during training. We will use these objective metrics to automatically evaluate the performance of the submitted test set samples provided by the authors.
For manual subjective evaluation, we assess the following aspects: identity consistency, video quality, lip synchronization, and speaking style controllability. Each item has a full score of 5 points, and the evaluation is carried out in the videos provided by the authors. These metrics quantitatively assess generation quality, temporal coherence, speed, and speaking style transferability in face video synthesis.
The final rankings of participants will be determined based on a combination of these objective and subjective scores, along with the model's inference speed demonstrated on the web demo page.
Reward
Top-ranked participants in this competition will receive a certificate of achievement, and will be recommended to submit a technical paper to ACM MM Asia 2025.
Commitment
We commit to establishing and maintaining an official GitHub page dedicated to this challenge, which will consistently provide all relevant challenge information, datasets, and task details for a minimum period of 4 years.
Organizers
• Donglin Di, Li Auto (didonglin@lixiang.com)
• Lei Fan, The University of New South Wales (lei.fan1@unsw.edu.au)
• Tonghua Su, Harbin Institute of Technology (thsu@hit.edu.cn)
• Yongjia Ma, Li Auto (maguire9993@gmail.com)
• He Feng, Harbin Institute of Technology (24b903117@stu.hit.edu.cn)
© 2025 ACM Multimedia Asia Conference. All Rights Reserved.